Imaginez que vous puissiez prédire, avant même sa publication, qu'un article scientifique va révolutionner son domaine. C'est exactement le défi que j'ai exploré lors de mon stage de recherche au laboratoire Bordeaux Sciences Économiques (Université de Bordeaux).
Le point de départ : un article de Nature Communications
En 2023, des chercheurs de l'Université de Chicago ont publié une découverte fascinante : les articles scientifiques qui combinent des idées inhabituelles ont jusqu'à 4 à 5 fois plus de chances de figurer parmi les publications les plus citées. Autrement dit, la surprise prédit l'impact.
Mais comment mesurer la "surprise" d'un article scientifique à grande échelle ?
L'idée clé : modéliser la science comme un réseau
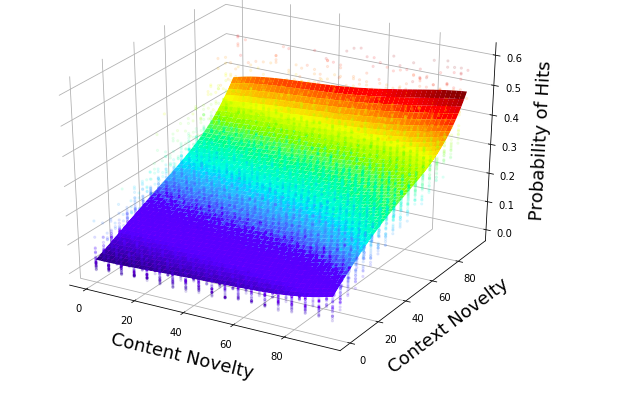
Chaque article scientifique combine deux choses : un contenu (les sujets traités, représentés par des mots-clés) et un contexte (les domaines scientifiques cités en référence). Les chercheurs ont modélisé ces combinaisons sous forme d'hypergraphe — une structure mathématique capable de représenter des relations entre plusieurs éléments simultanément, contrairement aux graphes classiques qui ne relient que deux éléments à la fois.
En entraînant un modèle sur les combinaisons passées, il devient possible de prédire lesquelles sont "attendues" — et donc d'identifier les combinaisons surprenantes quand elles apparaissent.
Mon travail : reproduire et étendre le modèle
Ma mission consistait d'abord à reproduire ce modèle sur notre infrastructure, puis à l'étendre : de 16,9 millions d'articles jusqu'en 2010 à 38,1 millions d'articles jusqu'en 2024. Une augmentation de 125% du volume de données.
Pour l'hypergraphe de contexte — basé sur les journaux cités — j'ai intégré la base de données NIH Open Citation Collection, ce qui a permis de passer d'une couverture de 50% à 76% des références bibliographiques, et de traiter près de 800 millions de relations de citation.
Les résultats ont confirmé et même légèrement amélioré ceux de l'étude originale, avec des scores AUC entre 0,97 et 0,999 selon les années.
Ce que les résultats confirment
Les articles avec les combinaisons de contenu les plus inattendues ont deux fois plus de chances d'être très cités. Ceux avec un contexte inattendu — c'est-à-dire qui citent des domaines éloignés de leur discipline — ont jusqu'à quatre fois plus de chances. Et quand les deux se combinent, cette probabilité peut atteindre 4,5 fois la moyenne.
En d'autres termes : les chercheurs qui osent sortir de leur domaine pour résoudre des problèmes d'un autre champ produisent souvent les travaux les plus influents.
Les défis techniques
Traiter 38 millions d'articles scientifiques n'est pas une mince affaire. Certains scripts ont tourné en continu pendant deux semaines, mobilisant jusqu'à 500 Go de RAM. J'ai également développé un système de clustering sémantique hiérarchique pour regrouper des millions de mots-clés en clusters thématiques cohérents, en utilisant des modèles de langage comme BioBERT et SciBERT.
Ce que ça change
Ce type de modèle ouvre des perspectives concrètes : identifier les recherches prometteuses avant qu'elles ne soient reconnues, aider les organismes de financement à mieux orienter leurs ressources, ou encore détecter les domaines scientifiques émergents en temps réel.
La science avance souvent là où on ne l'attend pas. L'IA peut nous aider à anticiper ces surprises.
Peut-on prédire les découvertes scientifiques ?
1 / 1